Go back to the projects page.
Summary
This analysis uses public EV chargepoint and plug-in vehicle (PiV) registration data to understand, by local authority district (LAD), which areas have the best and worst EV infrastructure.
What data is included?
First, four features are calculated to allow for initial exploration of the data. Details of these are as follows:
Count of PiVs
Source: DVLA and DfT dataset
- A simple count of registered PiVs by LAD is calculated.
- This includes all PiVs with
Privatekeepership. This excludes PiVs where the keepership isCompanyto avoid skewing the analysis with large quantities of fleet vehicles registered to a single address. - Where data has been suppressed in the raw file, the
[c]value has been replaced withNaN
Count of EV chargepoints
Source: Public EV chargepoint registry
- A simple count of public EV chargepoints by LAD is calculated.
- There has been no cleaning of this data beyond converting the
latitudeandlongitudeinto apoint. This is a public dataset and further accuracy has not been verified.
Ratio of PiVs to EV chargepoints
Source: Author’s calculations
- Taking the count of PiVs in each LAD and dividing this by the count of public EV chargepoints in each LAD.
- A higher ratio means there are more PiVs to each chargepoint and therefore public infrastructure may be lacking.
Average distance to nearest EV chargepoint
Source: Geographies from ONS via Open Geography Portal
- Using the population-weighted centroids (PWCs) for each output area (OA) within an LAD, the nearest public EV chargepoint is calculated. OA is the smallest census geography and contains between 40 and 250 households.
- Then this is aggregated to LAD level by taking the average distance of all OAs within the LAD to obtain the average distance to the nearest public EV chargepoint by LAD.
What do these features show?
The following choropleths map these four features. The absolute number of PiVs varies across England and Wales, with LADs across Wales, Lincolnshire and Cumbria having particularly low numbers. By contrast, the highest number of public EV chargepoints by LAD is concentrated in Greater London, with hotspots dotted elsewhere across the country. If we instead look at this as the ratio of PiVs to chargepoints, we again see the patterns change. Hotspots around the southeast of England highlight that there is potentially infrastructure lacking in these areas compared to PiV numbers. Lastly, we can see the average distance to the nearest chargepoint is perhaps unsurprisingly highest in rural areas, particularly in the north of England and Wales.
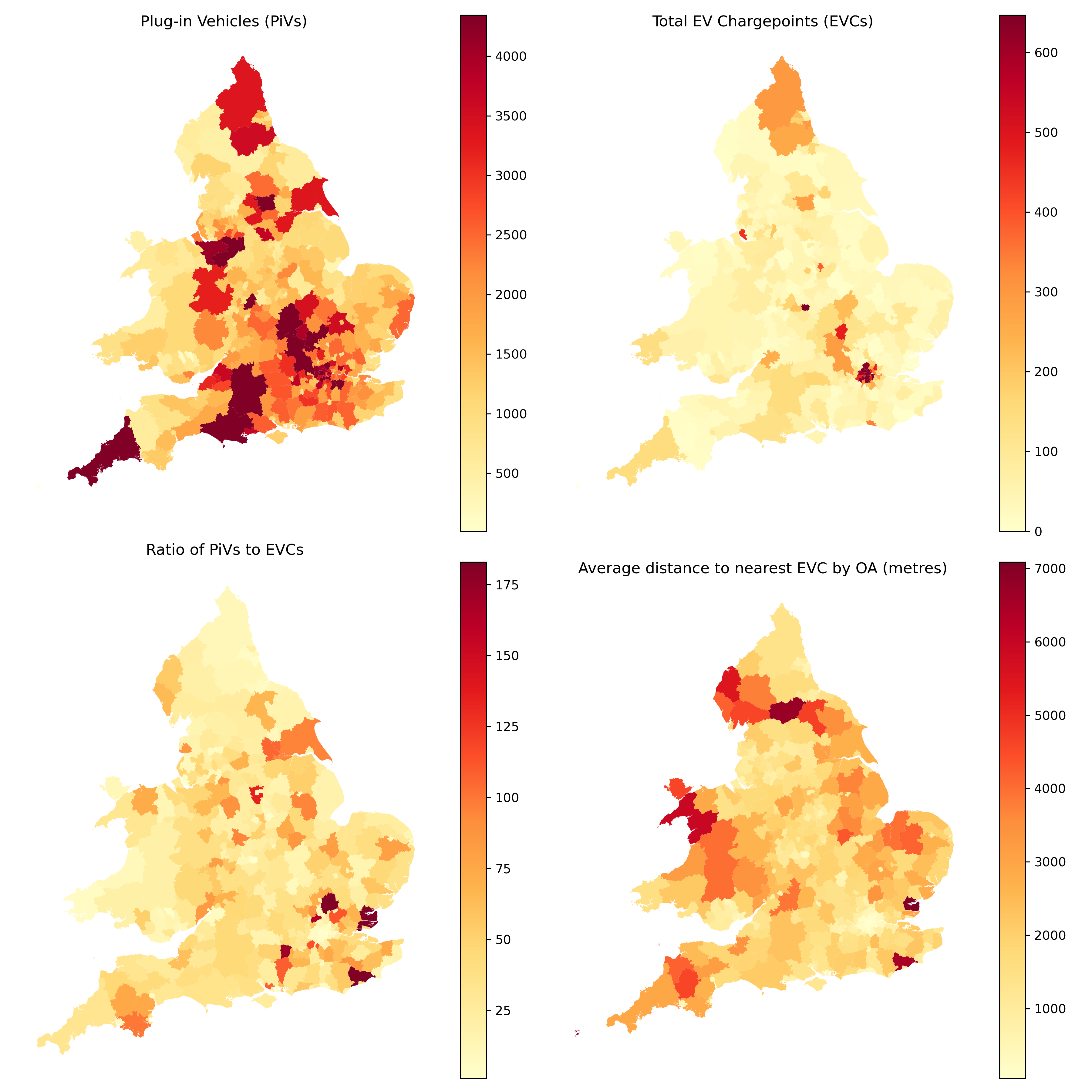
Code to create an interactive version of this map can be found below.
What is the relationship between the features?
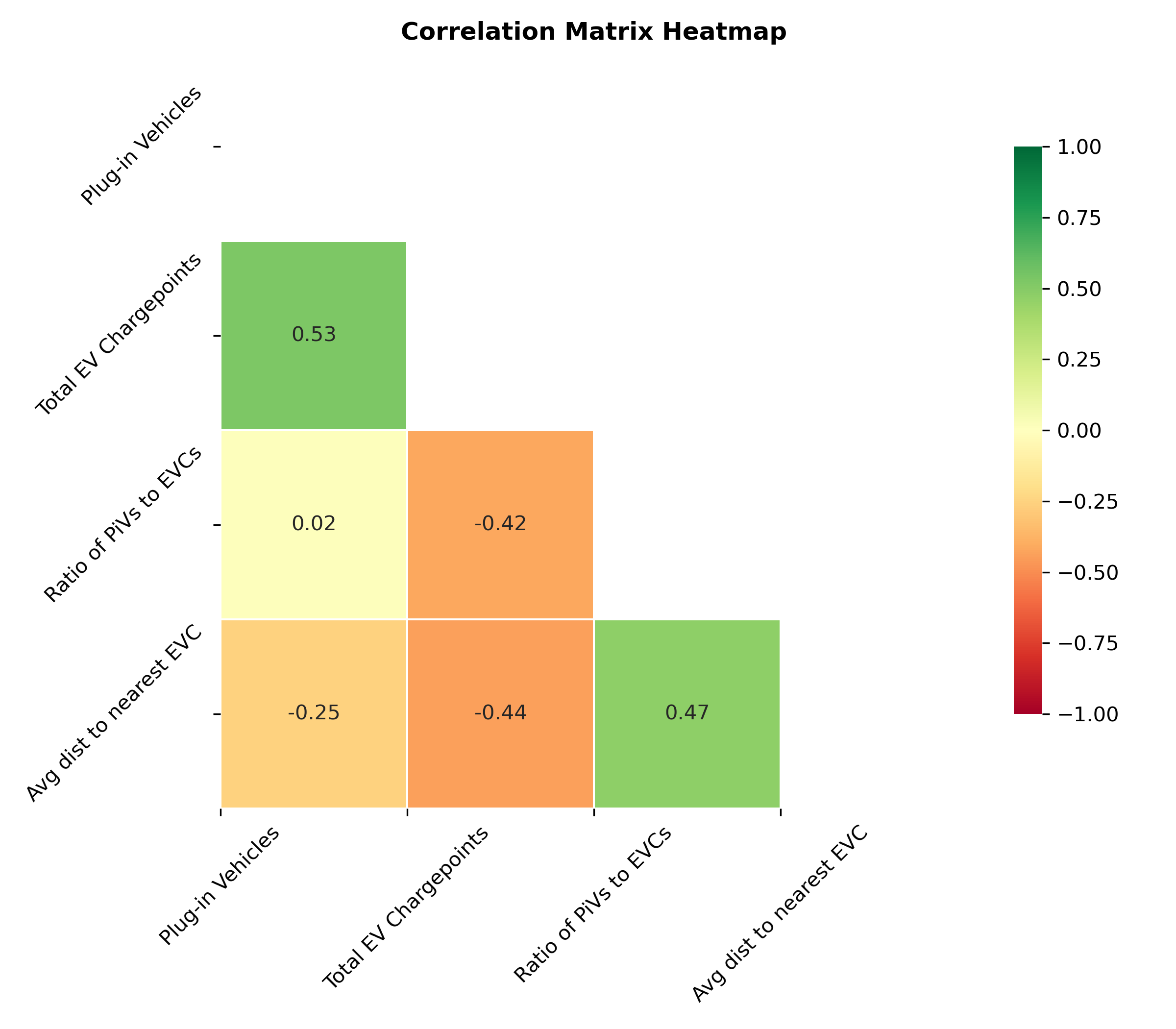
The correlation matrix heatmap below shows the relationship between each feature. There is some positive correlation between chargepoints and PiVs, which is good as this suggests that where there are more PiVs there tend to be more chargepoints. There is also some positive correlation between average distance to the nearest chargepoint and the ratio of PiVs to chargepoints. This means that if the distance is greater, there are also more PiVs to chargepoints perhaps suggesting these areas lack infrastructure.
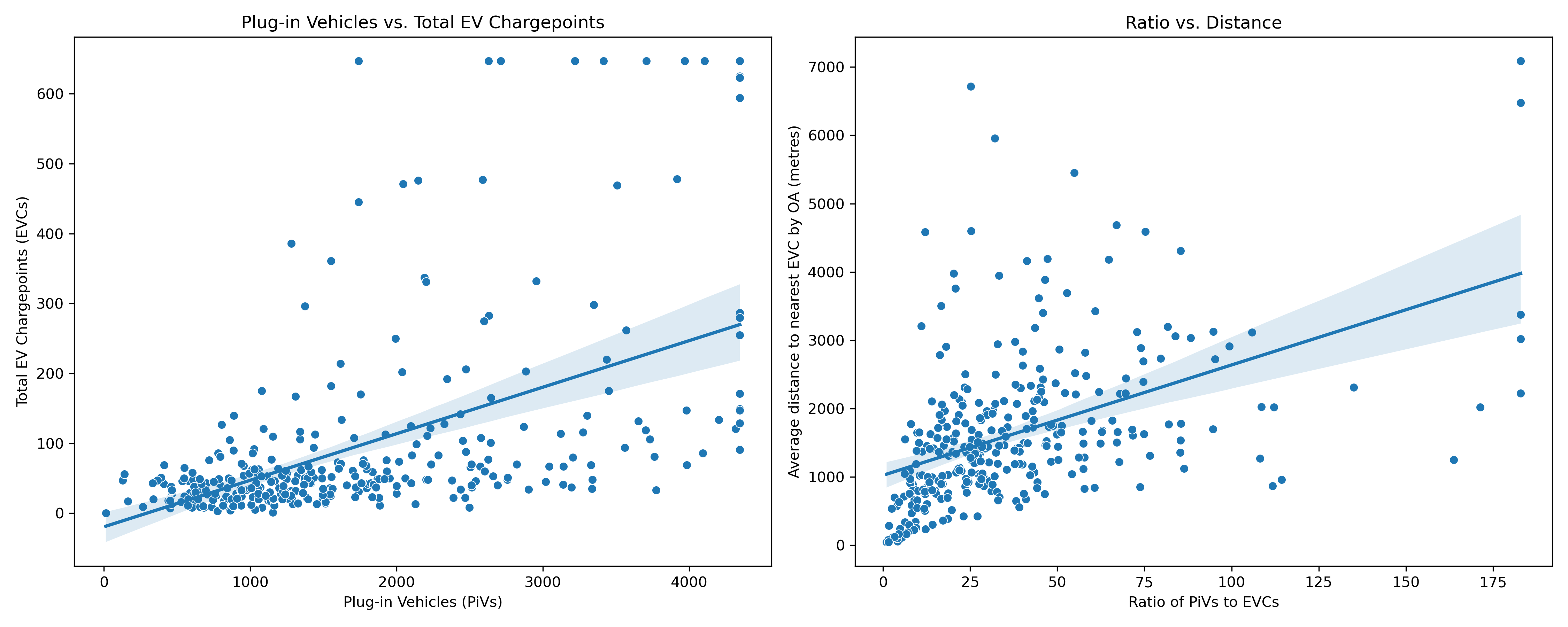
The following scatter plots illustrate this further, adding a regression line. We can see that there are outliers across both, with a cluster of LADs on the lower end.
So what does this mean for public EV infrastructure?
Taking the ratio of PiVs to public EV chargepoints and the average distance to the nearest chargepoint, a simple ranking is created combining the two. Areas with a high ratio of PiVs to chargepoints and a large distance to the nearest chargepoint could be lacking in public EV infrastructure.
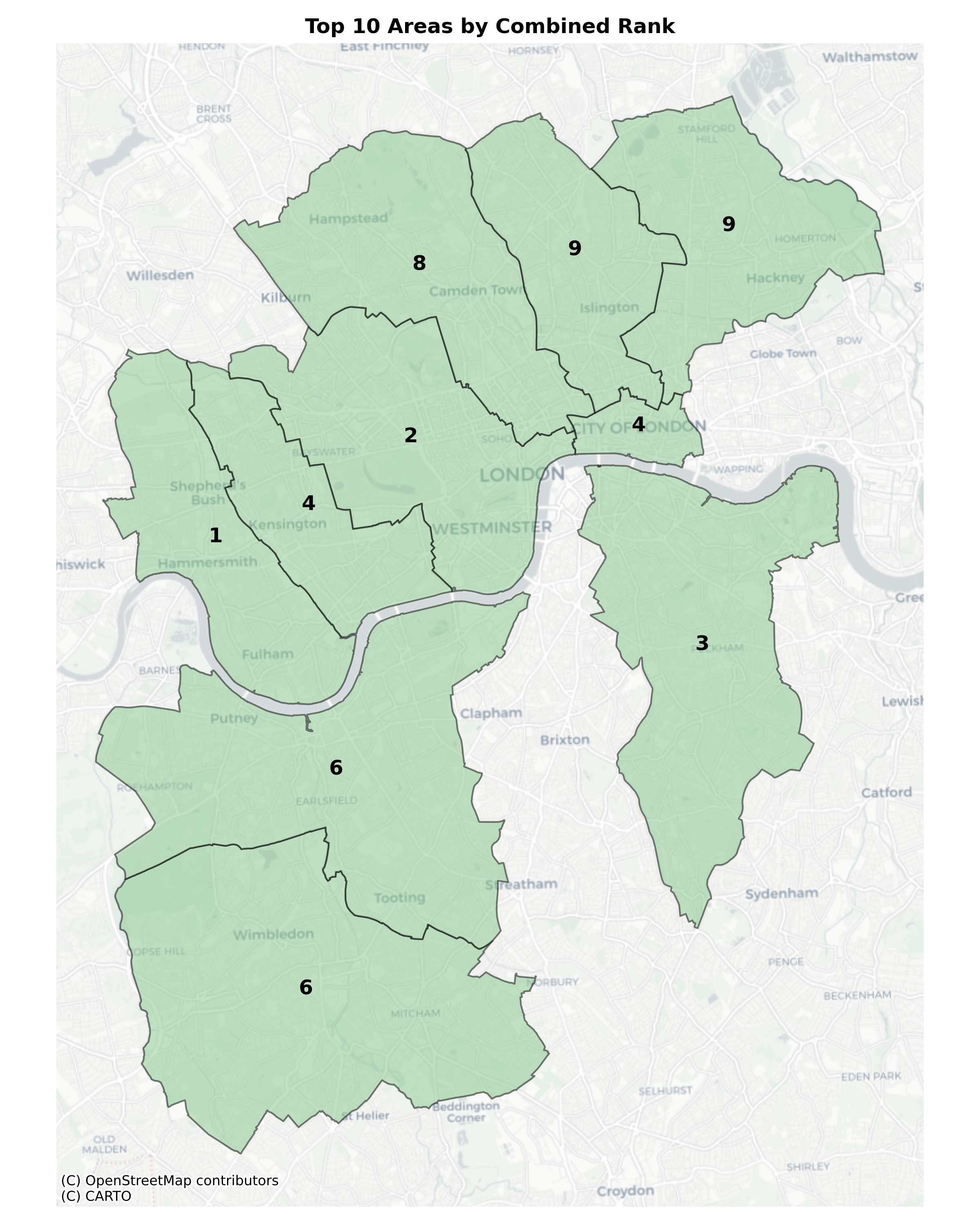
Top 10 The best performing LADs were all in London, suggesting infrastructure in the capital is well established.
| LAD22CD | LAD22NM | combined_rank | |
|---|---|---|---|
| 288 | E09000013 | Hammersmith and Fulham | 1.0 |
| 308 | E09000033 | Westminster | 2.0 |
| 303 | E09000028 | Southwark | 3.0 |
| 276 | E09000001 | City of London | 4.0 |
| 295 | E09000020 | Kensington and Chelsea | 4.0 |
| 299 | E09000024 | Merton | 6.0 |
| 307 | E09000032 | Wandsworth | 6.0 |
| 282 | E09000007 | Camden | 8.0 |
| 287 | E09000012 | Hackney | 9.0 |
| 294 | E09000019 | Islington | 9.0 |
Bottom 10 The worst performing LADs are more dispersed. Most are more rural areas, or include only one or two larger towns.
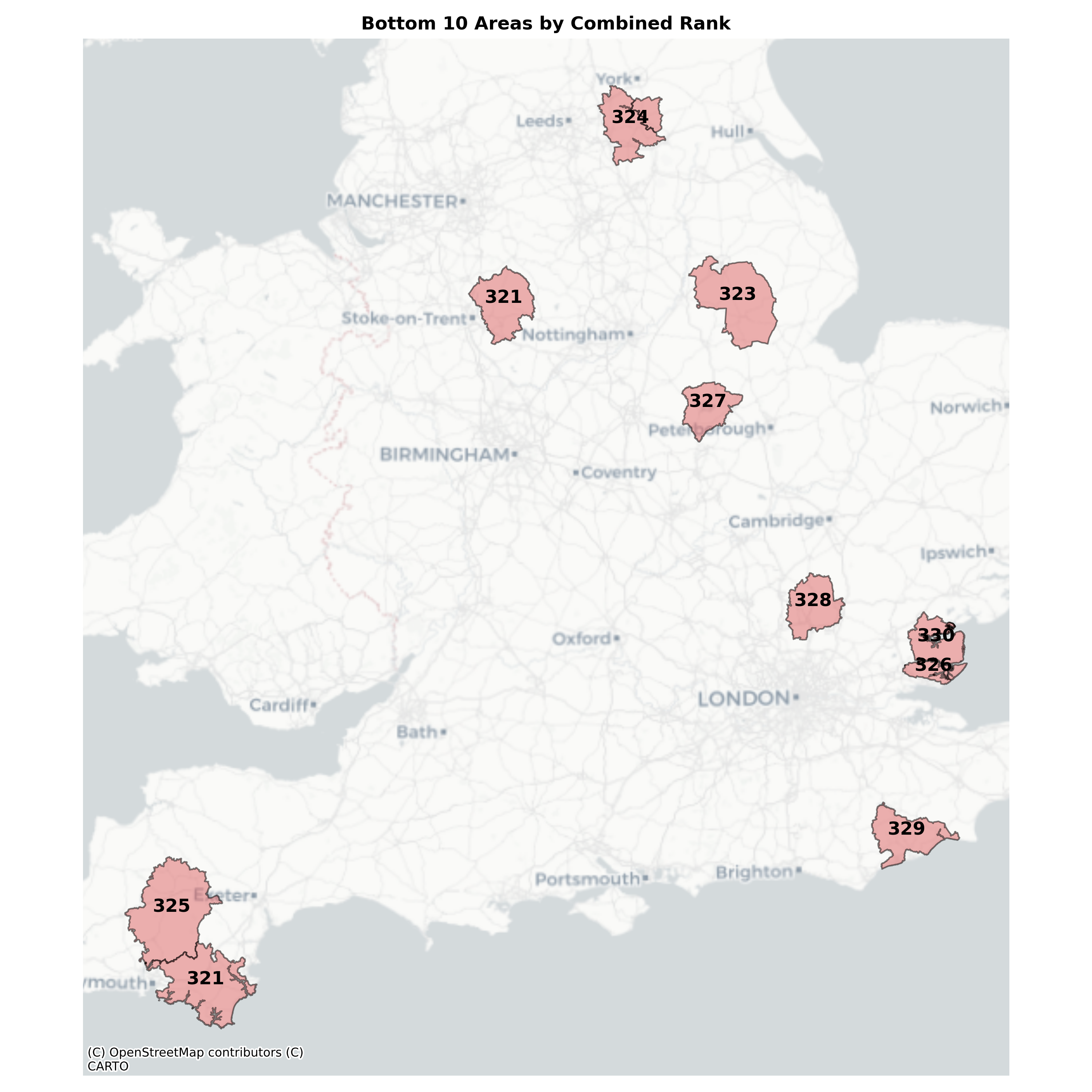
| LAD22CD | LAD22NM | combined_rank | |
|---|---|---|---|
| 99 | E07000074 | Maldon | 330.0 |
| 89 | E07000064 | Rother | 329.0 |
| 235 | E07000242 | East Hertfordshire | 328.0 |
| 16 | E06000017 | Rutland | 327.0 |
| 100 | E07000075 | Rochford | 326.0 |
| 85 | E07000047 | West Devon | 325.0 |
| 177 | E07000169 | Selby | 324.0 |
| 160 | E07000139 | North Kesteven | 323.0 |
| 82 | E07000044 | South Hams | 321.0 |
| 199 | E07000198 | Staffordshire Moorlands | 321.0 |
This information could be used by both public and private organisations alike to understand where public EV infrastructure is lacking and therefore incentivise installation of new infrastructure.
Considerations and future work
This analysis has demonstrated that current public EV structure may be lacking in some areas based on the current number of PiVs. This does not include:
- A temporal view of how PiV ownership has changed over time - there may be areas experiencing higher growth, with could arguably justify increased investment over other areas.
- EV infrastructure on private property (e.g. at home) - areas with a higher number of terraced houses or flats may require more public infrastructure as it can often be more challenging to install at these types of properties. Areas with higher rates of rented accomodation over private ownership could also face challenges as it would be the responsibility of the landlord to install EV chargepoints. Again, these areas may require more public infrastructure and so overlaying this data could be an interesting investigation to see how it affects the ranking.
The public EV chargepoint registry has also not been quality checked. Further investigation into this dataset and wrangling/cleaning as appropriate may impact results.
Coding
Import libraries
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
import numpy as np
import seaborn as sns
from scipy.stats import zscore
import matplotlib.pyplot as plt
import contextily as ctx
import foliumData wrangling
EV Chargepoint data
- Public EV chargepoint registry, available from: https://www.gov.uk/guidance/find-and-use-data-on-public-electric-vehicle-chargepoints
# Import csv
chargepoints_RAW = pd.read_csv('Data/national-charge-point-registry_230524.csv', low_memory=False)# Reduce to just required columns
chargepoints_TRIM = chargepoints_RAW[['chargeDeviceID','reference','name','latitude','longitude']]# Check length of df
len(chargepoints_TRIM)40580
# Visual check
chargepoints_TRIM.head()| chargeDeviceID | reference | name | latitude | longitude | |
|---|---|---|---|---|---|
| 0 | b86a77a42bb68c81946ec50cfc95e89d | 11172306P | Network Rail Westwood Centre 1 | 52.386590 | -1.587384 |
| 1 | dc1c347d471f68e41ad2a9a1145941d6 | APT-0296-0015/13P | Brindley Drive Car Park Birmingham - 70524 | 52.480918 | -1.907710 |
| 2 | 7d545ad9367ccb8a80c94a953314ae71 | CM123 | Renault Liverpool | 53.383579 | -2.977230 |
| 3 | 68c7fca1e3bba5e49ec90847dcdd456b | CM164 | NCP Portman Square | 51.516201 | -0.157996 |
| 4 | ac7a21c48f5833b33a5b606b2089e6a9 | CM167 | NCP Prince Street Car Park | 51.450340 | -2.596704 |
# Geocode locations using lat and long, set crs to 4326 and then convert to 27700 (British National Grid), drop lat and long
chargepoints_gdf = gpd.GeoDataFrame(chargepoints_TRIM,
geometry=gpd.points_from_xy(chargepoints_TRIM.longitude, chargepoints_TRIM.latitude)
).set_crs(epsg=4326, inplace=True).to_crs(epsg=27700).drop(columns=['latitude','longitude'])# Visual check
chargepoints_gdf.head()| chargeDeviceID | reference | name | geometry | |
|---|---|---|---|---|
| 0 | b86a77a42bb68c81946ec50cfc95e89d | 11172306P | Network Rail Westwood Centre 1 | POINT (428179.411 276586.797) |
| 1 | dc1c347d471f68e41ad2a9a1145941d6 | APT-0296-0015/13P | Brindley Drive Car Park Birmingham - 70524 | POINT (406364.849 287003.294) |
| 2 | 7d545ad9367ccb8a80c94a953314ae71 | CM123 | Renault Liverpool | POINT (335096.815 387859.900) |
| 3 | 68c7fca1e3bba5e49ec90847dcdd456b | CM164 | NCP Portman Square | POINT (527908.652 181305.630) |
| 4 | ac7a21c48f5833b33a5b606b2089e6a9 | CM167 | NCP Prince Street Car Park | POINT (358631.700 172541.813) |
EV Cars data
- df_VEH0145: Licensed plug-in vehicles (PiVs) at the end of the quarter by fuel type and lower super output area (LSOA): United Kingdom, available from: https://www.gov.uk/government/statistical-data-sets/vehicle-licensing-statistics-data-files
# Import csv
PiVs_RAW = pd.read_csv('Data/df_VEH0145.csv', low_memory=False)# Reduce to just required columns
PiVs_TRIM = PiVs_RAW[['LSOA11CD','LSOA11NM','Fuel','Keepership','2023 Q4']]# Visual check
PiVs_TRIM.head()| LSOA11CD | LSOA11NM | Fuel | Keepership | 2023 Q4 | |
|---|---|---|---|---|---|
| 0 | 95AA01S1 | Aldergrove 1 | Battery electric | Company | [c] |
| 1 | 95AA01S2 | Aldergrove 2 | Battery electric | Company | 9 |
| 2 | 95AA01S3 | Aldergrove 3 | Battery electric | Company | [c] |
| 3 | 95AA02W1 | Balloo | Battery electric | Company | 5 |
| 4 | 95AA03W1 | Ballycraigy | Battery electric | Company | [c] |
# Filter to all Fuel and private Keepership types, then drop those columns
PiVs_FILTERED = PiVs_TRIM[(PiVs_TRIM['Fuel'] == 'Total') &
(PiVs_TRIM['Keepership'] == 'Private')].drop(columns=['Fuel', 'Keepership'])# Replace the suppressed [c] data with NaN
PiVs_FILTERED['2023 Q4'] = PiVs_FILTERED['2023 Q4'].replace('[c]', np.nan)
# Convert the '2023 Q4' column to numeric data type
PiVs_FILTERED['2023 Q4'] = pd.to_numeric(PiVs_FILTERED['2023 Q4'])# Visual check
PiVs_FILTERED.head()| LSOA11CD | LSOA11NM | 2023 Q4 | |
|---|---|---|---|
| 189862 | 95AA01S1 | Aldergrove 1 | NaN |
| 189863 | 95AA01S2 | Aldergrove 2 | 15.0 |
| 189864 | 95AA01S3 | Aldergrove 3 | 19.0 |
| 189865 | 95AA02W1 | Balloo | 10.0 |
| 189866 | 95AA03W1 | Ballycraigy | NaN |
LSOA lookup
The PiV data uses the LSOA codes from 2011 and so this will need to be changed to the LSOA 2021 codes.
- LSOA best fit lookup 2011 to 2021, available from: https://geoportal.statistics.gov.uk/datasets/b14d449ba10a48508bd05cd4a9775e2b_0/explore
# Import csv
LSOA_lookup = pd.read_csv(
'Data/LSOA_(2011)_to_LSOA_(2021)_to_Local_Authority_District_(2022)_Best_Fit_Lookup_for_EW_(V2).csv',
low_memory=False)# Reduce to just required columns
LSOA_lookup = LSOA_lookup[['LSOA11CD','LSOA21CD','LAD22CD','LAD22NM']].copy()# Match 2021 to 2011 codes using lookup
PiVs_FILTERED = pd.merge(PiVs_FILTERED, LSOA_lookup, on='LSOA11CD')# Visual check
PiVs_FILTERED.head()| LSOA11CD | LSOA11NM | 2023 Q4 | LSOA21CD | LAD22CD | LAD22NM | |
|---|---|---|---|---|---|---|
| 0 | E01000001 | City of London 001A | 28.0 | E01000001 | E09000001 | City of London |
| 1 | E01000002 | City of London 001B | 30.0 | E01000002 | E09000001 | City of London |
| 2 | E01000003 | City of London 001C | 15.0 | E01000003 | E09000001 | City of London |
| 3 | E01000005 | City of London 001E | NaN | E01000005 | E09000001 | City of London |
| 4 | E01000006 | Barking and Dagenham 016A | 18.0 | E01000006 | E09000002 | Barking and Dagenham |
LADs
- LADs 2021 polygons, available from: https://geoportal.statistics.gov.uk/datasets/305779d69bf44feea05eeaa78ca26b5f_0/explore
# Import shp file
LADs = gpd.read_file('Data/Local_Authority_Districts_December_2022_UK_BFC_V2_-177113771882051469/LAD_DEC_2022_UK_BFC_V2.shp')# Reduce to just required columns
LADs = LADs[['LAD22CD','LAD22NM','geometry']].copy()# Visual check
LADs.head()| LAD22CD | LAD22NM | geometry | |
|---|---|---|---|
| 0 | E06000001 | Hartlepool | MULTIPOLYGON (((450154.599 525938.201, 450140…. |
| 1 | E06000002 | Middlesbrough | MULTIPOLYGON (((446854.700 517192.700, 446854…. |
| 2 | E06000003 | Redcar and Cleveland | MULTIPOLYGON (((451747.397 520561.100, 451792…. |
| 3 | E06000004 | Stockton-on-Tees | MULTIPOLYGON (((447177.704 517811.797, 447176…. |
| 4 | E06000005 | Darlington | POLYGON ((423496.602 524724.299, 423497.204 52… |
len(LADs)374
OAs
This analysis will use the population-weighted centroids (PWCs) to find the nearest EV chargepoints. This will then be aggregated to LAD level, so the OA to LAD lookup is required.
- OA 2021 PWCs, available from: https://geoportal.statistics.gov.uk/datasets/b9b2b2440af240ce9d30a1d39a7507c2_0/explore
- OA to LAD lookup, available from: https://geoportal.statistics.gov.uk/datasets/b9ca90c10aaa4b8d9791e9859a38ca67_0/explore
OA PWCs
# Import shp file
OA_PWC = gpd.read_file('Data/Output_Areas_2021_PWC_V3_-1981902074309169314/PopCentroids_EW_2021_V3.shp')# Reduce to just required columns
OA_PWC = OA_PWC[['OA21CD','geometry']].copy()OA to LAD lookup
# Import csv
OA_lookup = pd.read_csv(
'Data/Output_Area_to_Lower_layer_Super_Output_Area_to_Middle_layer_Super_Output_Area_to_Local_Authority_District_(December_2021)_Lookup_in_England_and_Wales_v3.csv',
low_memory=False)# Keep only required columns
OA_lookup = OA_lookup[['OA21CD','LSOA21CD','LAD22CD']].copy()# Visual check
OA_lookup.head()| OA21CD | LSOA21CD | LAD22CD | |
|---|---|---|---|
| 0 | E00060358 | E01011968 | E06000001 |
| 1 | E00060359 | E01011968 | E06000001 |
| 2 | E00060360 | E01011968 | E06000001 |
| 3 | E00060361 | E01011968 | E06000001 |
| 4 | E00060362 | E01011970 | E06000001 |
Feature engineering
Aggregate EV car ownership data to LAD
# Aggregate to LAD and calculate total number of PiVs
PiVs_LAD = PiVs_FILTERED.groupby('LAD22CD')['2023 Q4'].agg('sum').reset_index()
# Rename column to PiVs
PiVs_LAD.rename(columns={'2023 Q4': 'PiVs'}, inplace=True)# Visual check
PiVs_LAD.head()| LAD22CD | PiVs | |
|---|---|---|
| 0 | E06000001 | 410.0 |
| 1 | E06000002 | 391.0 |
| 2 | E06000003 | 580.0 |
| 3 | E06000004 | 1308.0 |
| 4 | E06000005 | 719.0 |
len(PiVs_LAD)331
Calculate distance to nearest chargepoint
- Using the OA PWCs, calculate the nearest EV chargepoint.
- Aggregate this to LAD level to get the average distance to the nearest chargepoint by LAD.
# Find the nearest chargepoint to each OA PWC and calculate distance in metres
OA_nearest_chargepoint = OA_PWC.sjoin_nearest(chargepoints_gdf, distance_col='distance', how='left')# Merge on OA_lookup_Leeds to get the LAD22CDs
OA_nearest_chargepoint = pd.merge(OA_nearest_chargepoint, OA_lookup, on='OA21CD', how='inner')# Keep only required columns
OA_nearest_chargepoint = OA_nearest_chargepoint[['OA21CD','geometry','distance','LAD22CD']].copy()# Aggregate to LAD and calculate average distance to nearest chargepoint
avg_dist_nearest_chargepoint_LAD = OA_nearest_chargepoint.groupby('LAD22CD')['distance'].agg('mean').reset_index()
# Rename column to avg_distance
avg_dist_nearest_chargepoint_LAD.rename(columns={'distance': 'avg_distance'}, inplace=True)# Visual check
avg_dist_nearest_chargepoint_LAD.head()| LAD22CD | avg_distance | |
|---|---|---|
| 0 | E06000001 | 1649.498055 |
| 1 | E06000002 | 1088.305461 |
| 2 | E06000003 | 1454.585351 |
| 3 | E06000004 | 911.259807 |
| 4 | E06000005 | 1188.923394 |
len(avg_dist_nearest_chargepoint_LAD)331
Calculate number of EV chargepoints in each LAD
- Aggregate the EV chargepoint data to LAD level to get total number of chargepoints in each LAD.
# Spatially match
chargepoints_LAD = gpd.sjoin(LADs, chargepoints_gdf, predicate='intersects')# Aggregate to LAD and calculate total number of chargepoints
chargepoints_LAD = chargepoints_LAD.groupby('LAD22CD')['index_right'].agg('count').reset_index()
# Rename column to total_chargepoints
chargepoints_LAD.rename(columns={'index_right': 'total_chargepoints'}, inplace=True)# Visual check
chargepoints_LAD.head()| LAD22CD | total_chargepoints | |
|---|---|---|
| 0 | E06000001 | 42 |
| 1 | E06000002 | 51 |
| 2 | E06000003 | 46 |
| 3 | E06000004 | 167 |
| 4 | E06000005 | 76 |
len(chargepoints_LAD)373
Calculate ratio of EV cars to chargepoints in each LAD
# Merge PiVs and chargepoint count dataframes
ratio_PiVs_to_chargepoints = pd.merge(PiVs_LAD, chargepoints_LAD, on='LAD22CD', how='left')
# Replace NaN values with 0 where there are no chargepoints in an MSOA
ratio_PiVs_to_chargepoints.fillna({'total_chargepoints': 0}, inplace=True)# Calculate ratio
ratio_PiVs_to_chargepoints['ratio_PiVs_to_chargepoints'] = (
ratio_PiVs_to_chargepoints['PiVs'] / ratio_PiVs_to_chargepoints['total_chargepoints'])
# Replace 'inf' with NaN
ratio_PiVs_to_chargepoints['ratio_PiVs_to_chargepoints'] = ratio_PiVs_to_chargepoints[
'ratio_PiVs_to_chargepoints'].replace([np.inf, -np.inf], np.nan)Add average distance and LAD polygon to final dataframe
# Add nearest chargepoint
final_df = pd.merge(ratio_PiVs_to_chargepoints,avg_dist_nearest_chargepoint_LAD, on='LAD22CD')
# Add LAD polygons
final_df = pd.merge(LADs, final_df, on='LAD22CD')# Visual check
final_df.head()| LAD22CD | LAD22NM | geometry | PiVs | total_chargepoints | ratio_PiVs_to_chargepoints | avg_distance | |
|---|---|---|---|---|---|---|---|
| 0 | E06000001 | Hartlepool | MULTIPOLYGON (((450154.599 525938.201, 450140…. | 410.0 | 42.0 | 9.761905 | 1649.498055 |
| 1 | E06000002 | Middlesbrough | MULTIPOLYGON (((446854.700 517192.700, 446854…. | 391.0 | 51.0 | 7.666667 | 1088.305461 |
| 2 | E06000003 | Redcar and Cleveland | MULTIPOLYGON (((451747.397 520561.100, 451792…. | 580.0 | 46.0 | 12.608696 | 1454.585351 |
| 3 | E06000004 | Stockton-on-Tees | MULTIPOLYGON (((447177.704 517811.797, 447176…. | 1308.0 | 167.0 | 7.832335 | 911.259807 |
| 4 | E06000005 | Darlington | POLYGON ((423496.602 524724.299, 423497.204 52… | 719.0 | 76.0 | 9.460526 | 1188.923394 |
Handle outliers
There are some outliers on the top end, so anything outside 2sd will be amended.
# Loop through each variable and calculate mean, std, and threshold
for variable in ['PiVs', 'total_chargepoints', 'ratio_PiVs_to_chargepoints', 'avg_distance']:
mean_var = final_df[variable].mean()
std_var = final_df[variable].std()
threshold_var = mean_var + 2 * std_var
# Create new column based on outlier condition
final_df[f'amended_{variable}'] = final_df[variable].apply(lambda x: threshold_var if x > threshold_var else x)# Visual check
final_df.head()| LAD22CD | LAD22NM | geometry | PiVs | total_chargepoints | ratio_PiVs_to_chargepoints | avg_distance | amended_PiVs | amended_total_chargepoints | amended_ratio_PiVs_to_chargepoints | amended_avg_distance | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | E06000001 | Hartlepool | MULTIPOLYGON (((450154.599 525938.201, 450140…. | 410.0 | 42.0 | 9.761905 | 1649.498055 | 410.0 | 42.0 | 9.761905 | 1649.498055 |
| 1 | E06000002 | Middlesbrough | MULTIPOLYGON (((446854.700 517192.700, 446854…. | 391.0 | 51.0 | 7.666667 | 1088.305461 | 391.0 | 51.0 | 7.666667 | 1088.305461 |
| 2 | E06000003 | Redcar and Cleveland | MULTIPOLYGON (((451747.397 520561.100, 451792…. | 580.0 | 46.0 | 12.608696 | 1454.585351 | 580.0 | 46.0 | 12.608696 | 1454.585351 |
| 3 | E06000004 | Stockton-on-Tees | MULTIPOLYGON (((447177.704 517811.797, 447176…. | 1308.0 | 167.0 | 7.832335 | 911.259807 | 1308.0 | 167.0 | 7.832335 | 911.259807 |
| 4 | E06000005 | Darlington | POLYGON ((423496.602 524724.299, 423497.204 52… | 719.0 | 76.0 | 9.460526 | 1188.923394 | 719.0 | 76.0 | 9.460526 | 1188.923394 |
Visualising data
The following code builds an interactive map of the features in final_df. This is saved down into an Outputs/ folder as an HTML file.
# Create the individual layers
m = final_df.explore(
column="amended_PiVs",
scheme="naturalbreaks",
cmap='YlOrRd',
legend=False,
k=10,
tooltip=["LAD22CD", "LAD22NM", "amended_PiVs"],
style_kwds=dict(color='black', weight=0.5, fillOpacity=0.8),
highlight_kwds=dict(fillOpacity=1),
name="Plug-in Vehicles",
show=True)
final_df.explore(
m=m,
column="amended_total_chargepoints",
scheme="naturalbreaks",
cmap='YlOrRd',
legend=False,
k=10,
tooltip=["LAD22CD", "LAD22NM", "amended_total_chargepoints"],
style_kwds=dict(color='black', weight=0.5, fillOpacity=0.8),
highlight_kwds=dict(fillOpacity=1),
name="Total EV Chargepoints",
show=False)
final_df.explore(
m=m,
column="amended_ratio_PiVs_to_chargepoints",
scheme="naturalbreaks",
cmap='YlOrRd',
legend=False,
k=10,
tooltip=["LAD22CD", "LAD22NM", "amended_ratio_PiVs_to_chargepoints"],
style_kwds=dict(color='black', weight=0.5, fillOpacity=0.8),
highlight_kwds=dict(fillOpacity=1),
name="Ratio of Plug-in Vehicles to EV Chargepoints",
show=False)
final_df.explore(
m=m,
column="amended_avg_distance",
scheme="naturalbreaks",
cmap='YlOrRd',
legend=False,
k=10,
tooltip=["LAD22CD", "LAD22NM", "amended_avg_distance"],
style_kwds=dict(color='black', weight=0.5, fillOpacity=0.8),
highlight_kwds=dict(fillOpacity=1),
name="Average distance to nearest EV Chargepoint by OA",
show=False)
# Add the map base
folium.TileLayer("CartoDB positron", show=True).add_to(m)
# Add layer control to map
folium.LayerControl().add_to(m)
# Save the map to an HTML file
m.save("Outputs/Interactive_map.html")The following code builds four choropleth maps of the features in final_df. This is saved down into an Outputs/ folder as a .png file.
# Create 2x2 subplots
fig, axs = plt.subplots(2, 2, figsize=(12, 12))
# Define aliases for column names
column_aliases = {
'amended_PiVs': 'Plug-in Vehicles (PiVs)',
'amended_total_chargepoints': 'Total EV Chargepoints (EVCs)',
'amended_ratio_PiVs_to_chargepoints': 'Ratio of PiVs to EVCs',
'amended_avg_distance': 'Average distance to nearest EVC by OA (metres)'
}
# Loop through each variable and corresponding subplot
variables = list(column_aliases.keys())
for variable, ax in zip(variables, axs.flatten()):
final_df.plot(column=variable, cmap='YlOrRd', ax=ax, legend=True)
ax.set_title(f'{column_aliases[variable]}') # Set the title using the alias
ax.set_axis_off() # Turn off axis
plt.subplots_adjust(wspace=0.05, hspace=0.05) # Adjust space between subplots
plt.tight_layout() # Adjust layout to prevent overlap
# Export to Outputs/ folder
plt.savefig('Outputs/Feature_choropleths.png', dpi=300)
# Close figure
plt.close(fig)The following code creates two scatterplots with regression lines for selected features from the final_df. This is saved down into an Outputs/ folder as a .png file.
# Create a subplot grid with 1 row and 2 columns
fig, axs = plt.subplots(1, 2, figsize=(15, 6))
# Plot the first scatter plot
sns.scatterplot(x='amended_PiVs', y='amended_total_chargepoints', data=final_df, ax=axs[0])
sns.regplot(x='amended_PiVs', y='amended_total_chargepoints', data=final_df, scatter=False, ax=axs[0])
axs[0].set_xlabel(column_aliases['amended_PiVs']) # Set x-axis label using alias
axs[0].set_ylabel(column_aliases['amended_total_chargepoints']) # Set y-axis label using alias
axs[0].set_title('Plug-in Vehicles vs. Total EV Chargepoints') # Set the title
# Plot the second scatter plot
sns.scatterplot(x='amended_ratio_PiVs_to_chargepoints', y='amended_avg_distance', data=final_df, ax=axs[1])
sns.regplot(x='amended_ratio_PiVs_to_chargepoints', y='amended_avg_distance', data=final_df, scatter=False, ax=axs[1])
axs[1].set_xlabel(column_aliases['amended_ratio_PiVs_to_chargepoints']) # Set x-axis label using alias
axs[1].set_ylabel(column_aliases['amended_avg_distance']) # Set y-axis label using alias
axs[1].set_title('Ratio vs. Distance') # Set the title
# Adjust layout
plt.tight_layout()
# Export to Outputs/ folder
plt.savefig('Outputs/Scatter_Reg_Plots.png', dpi=300)
# Close figure
plt.close(fig)The following code creates a correlation matrix heatmap of the features in final_df. This is saved down into an Outputs/ folder as a .png file.
# Calculate the correlation matrix
correlation_matrix = final_df[[
'amended_PiVs','amended_total_chargepoints',
'amended_ratio_PiVs_to_chargepoints','amended_avg_distance']].corr()
# Generate a mask for the diagonal cells
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool))
# Generate a heatmap
plt.figure(figsize=(8, 7))
sns.heatmap(correlation_matrix, cmap='RdYlGn', annot=True,
fmt=".2f", mask=mask, vmin=-1, vmax=1, cbar_kws={"shrink": 0.75}, linewidth=.5)
# Rotate axis labels
plt.xticks(rotation=45)
plt.yticks(rotation=45)
# Set axis labels using aliases and wrap text
plt.xticks(ticks=range(len(correlation_matrix.columns)),
labels=['Plug-in Vehicles',
'Total EV Chargepoints',
'Ratio of PiVs to EVCs',
'Avg dist to nearest EVC'])
plt.yticks(ticks=np.arange(len(correlation_matrix.columns))+0.5,
labels=['Plug-in Vehicles',
'Total EV Chargepoints',
'Ratio of PiVs to EVCs',
'Avg dist to nearest EVC'])
plt.title('Correlation Matrix Heatmap', fontweight='bold')
plt.tight_layout()
# Export to Outputs/ folder
plt.savefig('Outputs/CorrelationMatrix.png', dpi=300)
# Close figure
plt.close()Creating a ranking
The following code creates a simple ranking of LADs based on:
- Average distance to the nearest EV chargepoint
- Ratio of Plug-in vehicles to EV chargepoints
The idea is that if the average distance is high, and the ratio is high, then these areas may be lacking public EV infrastructure.
# Create a new dataframe containing just the amended features for the ranking
ranking = final_df.drop(final_df.columns[3:9], axis=1)# Rank the values in each column
ranking['rank_ratio'] = ranking['amended_ratio_PiVs_to_chargepoints'].rank(ascending=True, method='min')
ranking['rank_distance'] = ranking['amended_avg_distance'].rank(ascending=True, method='min')# Compute the combined ranking
ranking['combined_rank'] = (ranking['rank_ratio'] + ranking['rank_distance']) / 2
ranking['combined_rank'] = ranking['combined_rank'].rank(ascending=True, method='min')The following code creates a map of the top 10 combined_rank LADs in ranking. This is saved down into an Outputs/ folder as a .png file.
# Get top 10 areas
ranking[['LAD22CD','LAD22NM','combined_rank']].sort_values(by='combined_rank', ascending=True).head(10)| LAD22CD | LAD22NM | combined_rank | |
|---|---|---|---|
| 288 | E09000013 | Hammersmith and Fulham | 1.0 |
| 308 | E09000033 | Westminster | 2.0 |
| 303 | E09000028 | Southwark | 3.0 |
| 276 | E09000001 | City of London | 4.0 |
| 295 | E09000020 | Kensington and Chelsea | 4.0 |
| 299 | E09000024 | Merton | 6.0 |
| 307 | E09000032 | Wandsworth | 6.0 |
| 282 | E09000007 | Camden | 8.0 |
| 287 | E09000012 | Hackney | 9.0 |
| 294 | E09000019 | Islington | 9.0 |
# Sort and select the top 10 areas
top_10_areas = ranking.sort_values(by='combined_rank', ascending=True).head(10)
# Plot only the top 10 areas
fig, ax = plt.subplots(1, 1, figsize=(8, 10))
top_10_areas.plot(ax=ax, color='#88C88E', edgecolor='black', linewidth=1, legend=True, alpha=0.5)
# Annotate the top 10 areas with their rank
for idx, row in top_10_areas.iterrows():
plt.annotate(text=int(row['combined_rank']), xy=(row.geometry.centroid.x, row.geometry.centroid.y),
horizontalalignment='center', fontsize=12, weight='bold', color='black')
# Plot basemap
ctx.add_basemap(ax, crs=top_10_areas.crs.to_string(), source=ctx.providers.CartoDB.Positron)
# Set title and remove axis
ax.set_title('Top 10 Areas by Combined Rank', fontsize=12, fontweight='bold')
ax.set_axis_off()
# Adjust layout
plt.tight_layout()
# Export to Outputs/ folder
plt.savefig('Outputs/Map_of_Top_10.png', dpi=300)
# Close figure
plt.close(fig)The following code creates a map of the bottom 10 combined_rank LADs in ranking. This is saved down into an Outputs/ folder as a .png file.
# Show bottom 10 areas
ranking[['LAD22CD','LAD22NM','combined_rank']].sort_values(by='combined_rank', ascending=False).head(10)| LAD22CD | LAD22NM | combined_rank | |
|---|---|---|---|
| 99 | E07000074 | Maldon | 330.0 |
| 89 | E07000064 | Rother | 329.0 |
| 235 | E07000242 | East Hertfordshire | 328.0 |
| 16 | E06000017 | Rutland | 327.0 |
| 100 | E07000075 | Rochford | 326.0 |
| 85 | E07000047 | West Devon | 325.0 |
| 177 | E07000169 | Selby | 324.0 |
| 160 | E07000139 | North Kesteven | 323.0 |
| 82 | E07000044 | South Hams | 321.0 |
| 199 | E07000198 | Staffordshire Moorlands | 321.0 |
# Sort and select the bottom 10 areas
bottom_10_areas = ranking.sort_values(by='combined_rank', ascending=False).head(10)
# Plot only the top 10 areas
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
bottom_10_areas.plot(ax=ax, color='#DE6464', edgecolor='black', linewidth=1, legend=True, alpha=0.5)
# Annotate the top 10 areas with their rank
for idx, row in bottom_10_areas.iterrows():
plt.annotate(text=int(row['combined_rank']), xy=(row.geometry.centroid.x, row.geometry.centroid.y),
horizontalalignment='center', fontsize=12, weight='bold', color='black')
# Plot basemap
ctx.add_basemap(ax, crs=bottom_10_areas.crs.to_string(), source=ctx.providers.CartoDB.Positron)
# Set title and remove axis
ax.set_title('Bottom 10 Areas by Combined Rank', fontsize=12, fontweight='bold')
ax.set_axis_off()
# Adjust layout
plt.tight_layout()
# Export to Outputs/ folder
plt.savefig('Outputs/Map_of_Bottom_10.png', dpi=300)
# Close figure
plt.close(fig)